
Diagnosis
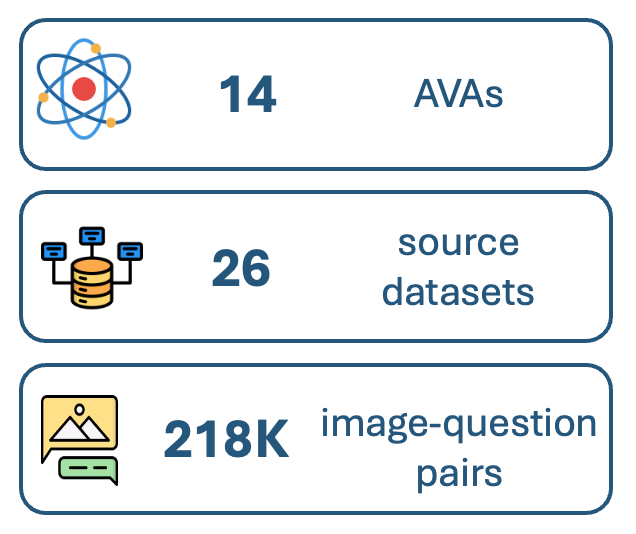
14 AVAs pinpoint visual strengths and weaknesses.
CVPR 2026
* Equal contribution
TL;DR: AVA-Bench is a diagnostic benchmark for Vision Foundation Models (VFMs) that breaks visual understanding into 14 Atomic Visual Abilities, such as localization, counting, depth, OCR, and spatial reasoning. Instead of asking which VFM is best overall, AVA-Bench reveals where each model excels or fails, enabling principled VFM selection for downstream applications.
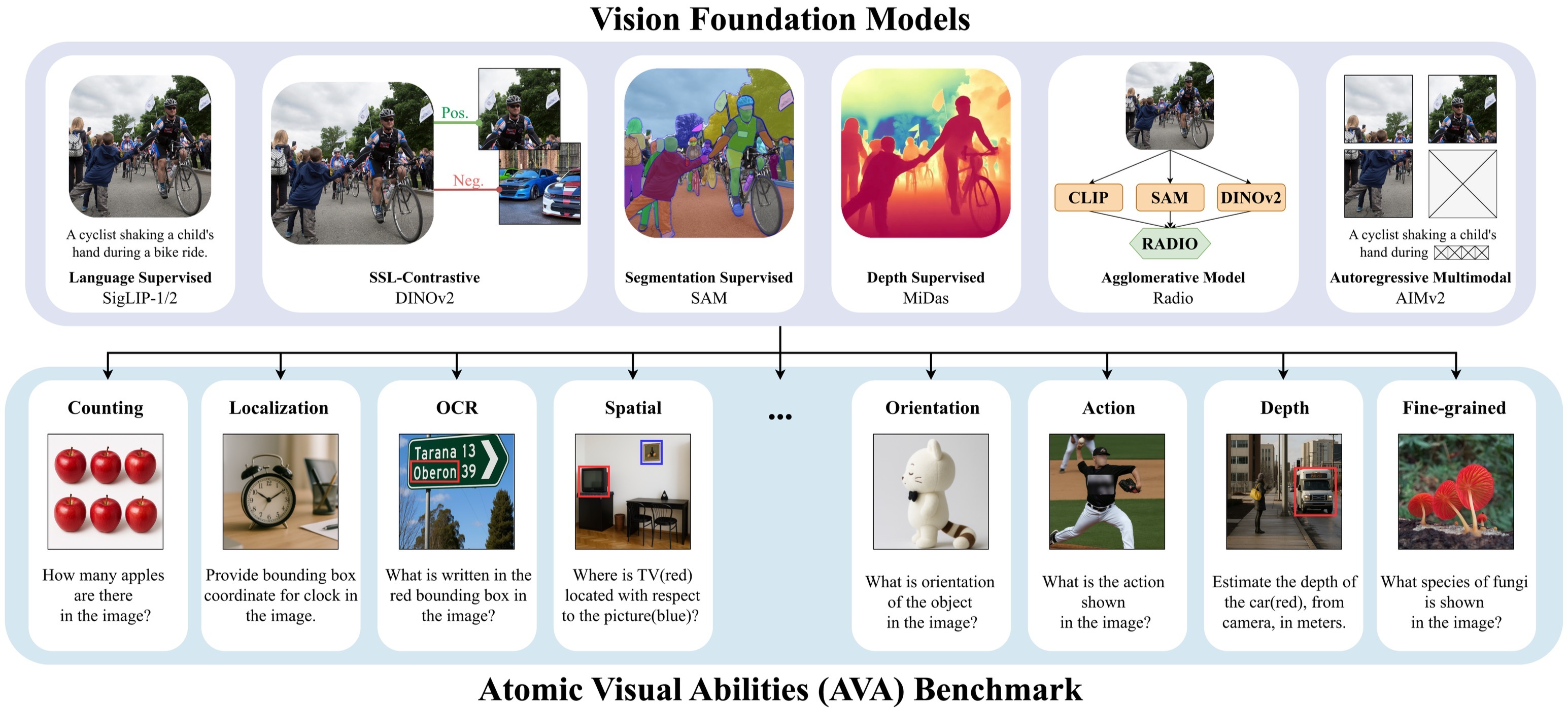
14 AVAs pinpoint visual strengths and weaknesses.

Ability fingerprints reveal VFM fits for applications.

Efficient evaluation and an open-source benchmark.
AVAs are fundamental visual abilities (e.g., counting, localization, depth estimation), enabling complex visual reasoning tasks.
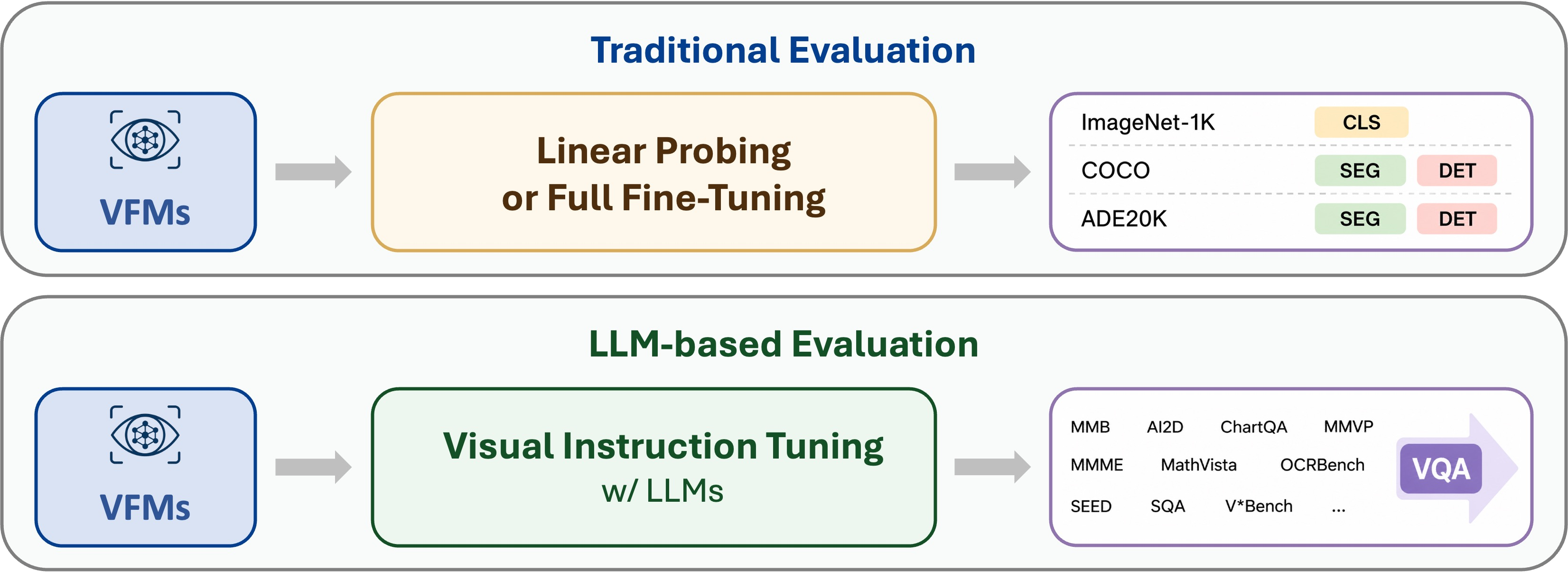
Traditional evaluation uses task-specific heads, such as linear probing or full fine-tuning, for each downstream task.
LLM-based evaluation uses visual instruction tuning with LLMs, then tests VFMs on diverse VQA benchmarks.
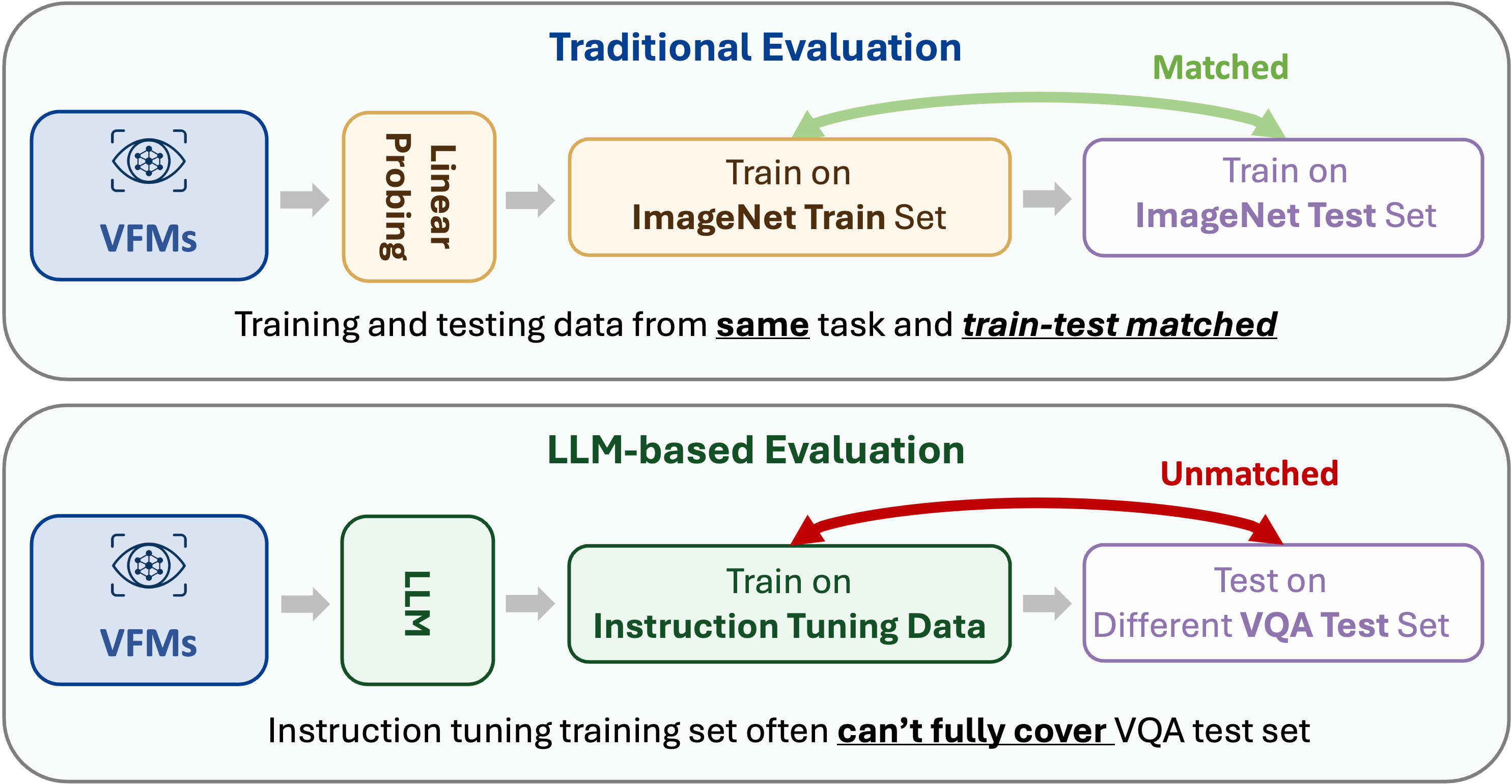
A wrong prediction may arise from train-test mismatch rather than genuine visual deficiencies in a VFM.

VQA questions often require multiple abilities simultaneously, making it hard to attribute a failure to missing abilities or one single critical ability.
AVA-Bench is the first systematic evaluation explicitly disentangling 14 Atomic Visual Abilities (AVAs) for VFMs.
AVAs are fundamental perceptual capabilities that can be combined to address more complex visual reasoning tasks.

Each AVA comes with train-test-matched data.
Given an AVA, image-question pairs are carefully designed to test only that AVA.
This eliminates the two blind spots and lets AVA-Bench pinpoint exactly where a VFM excels or falters.

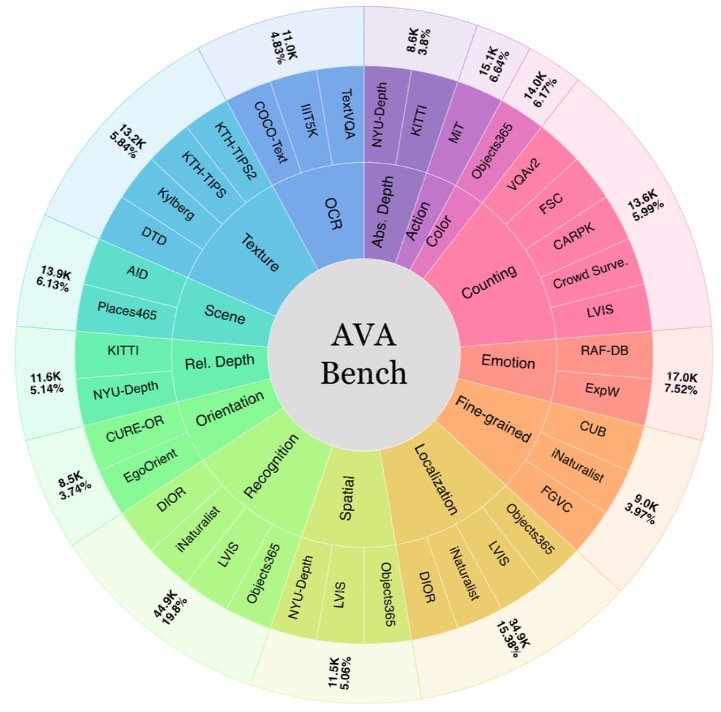
AVA-Bench carefully controls dataset balance, object visibility, and annotation biases.
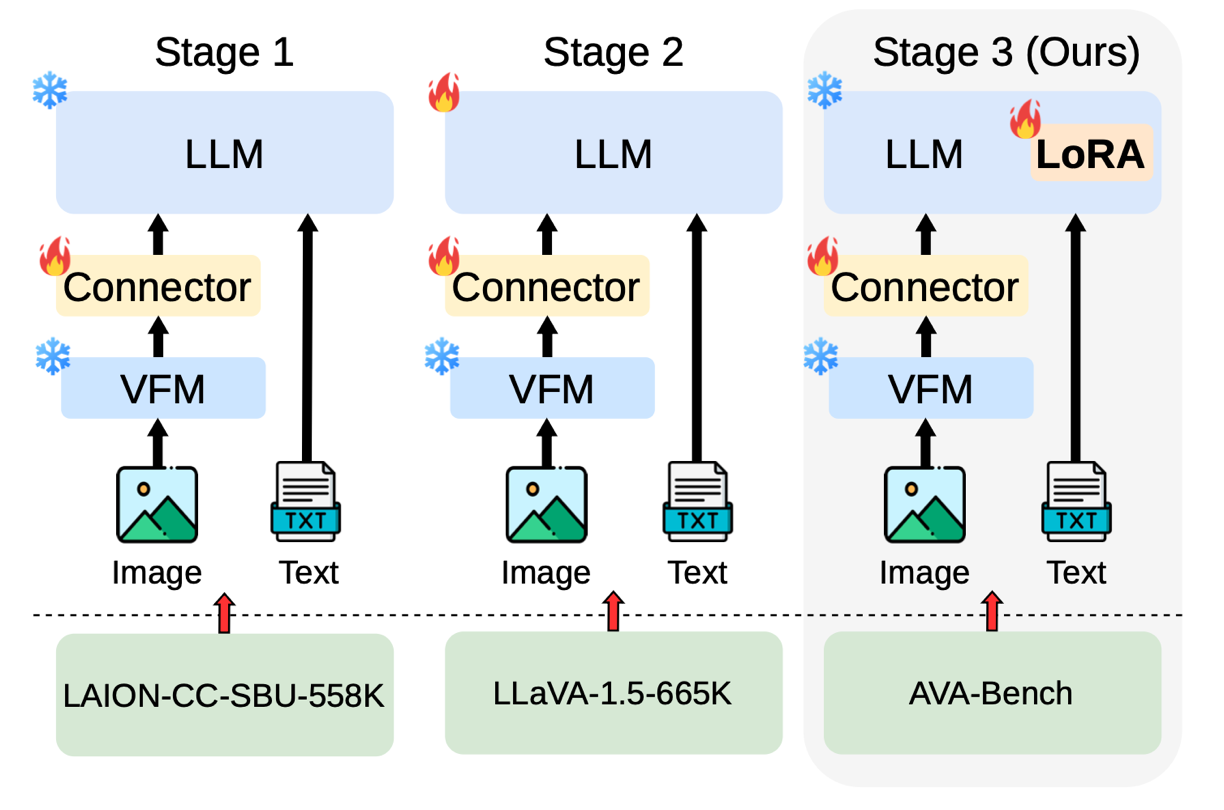
Our evaluation follows an LLaVA-style interface, and the VFM remains frozen.
Following LLaVA's two-stage training (connector pretraining and instruction tuning), AVA-Bench adds a third stage: for each ability, train only the connector and a small LoRA module in the LLM, then evaluate on that ability-specific test set.
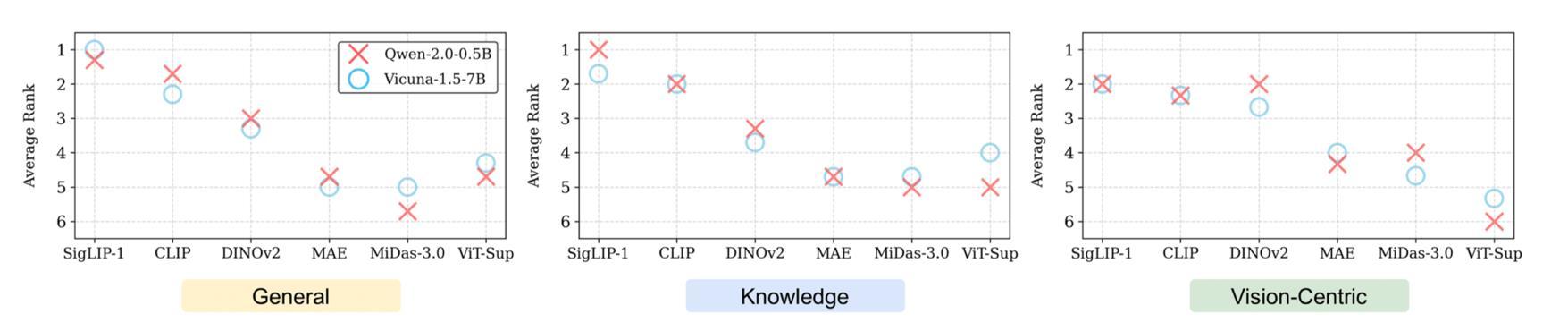
A heavyweight LLM may NOT be required for reliable comparative evaluations.
Preserves similar relative VFM rankings to a 7B Vicuna.
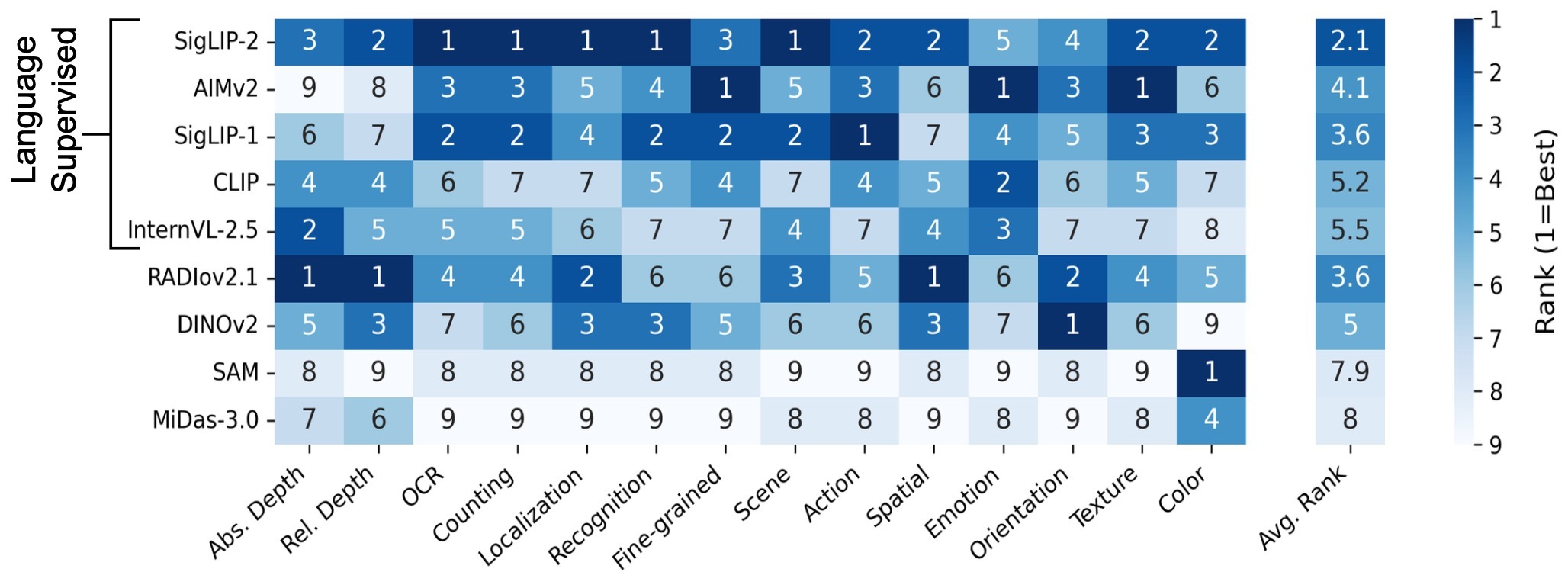
Each VFM has an AVA fingerprint.
Language-supervised VFMs excel broadly across AVAs.
Even weaker VFMs perform well in at least one AVA.
Composite task failures typically stem from specific AVA deficiencies rather than general visual incompetence.

Where is the dog (annotated by the red box) located with respect to the plane (annotated by the blue box)?
A. Left above B. Left below C. Right above D. Right below.

Where is the dog located with respect to the plane?
A. Left above B. Left below C. Right above D. Right below.
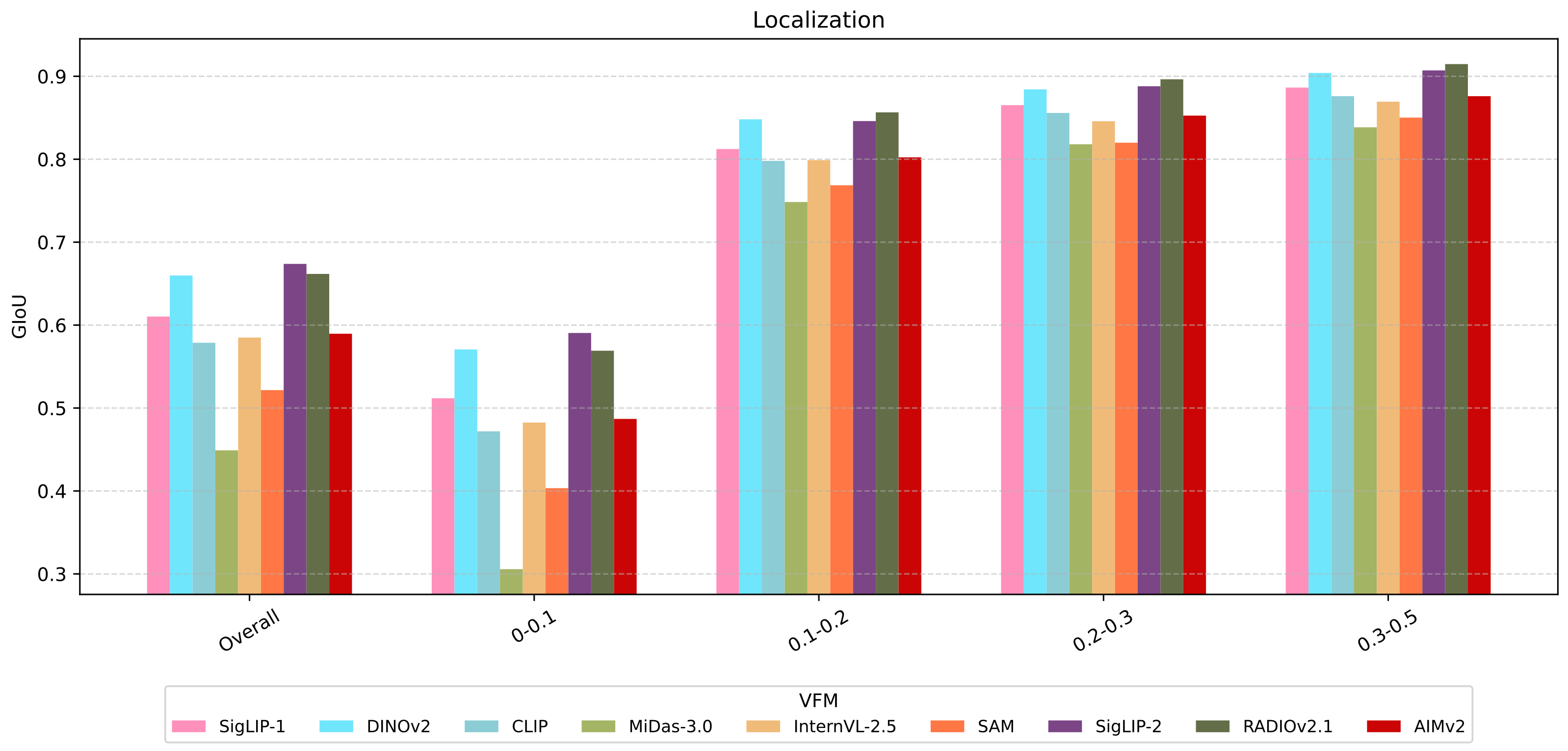
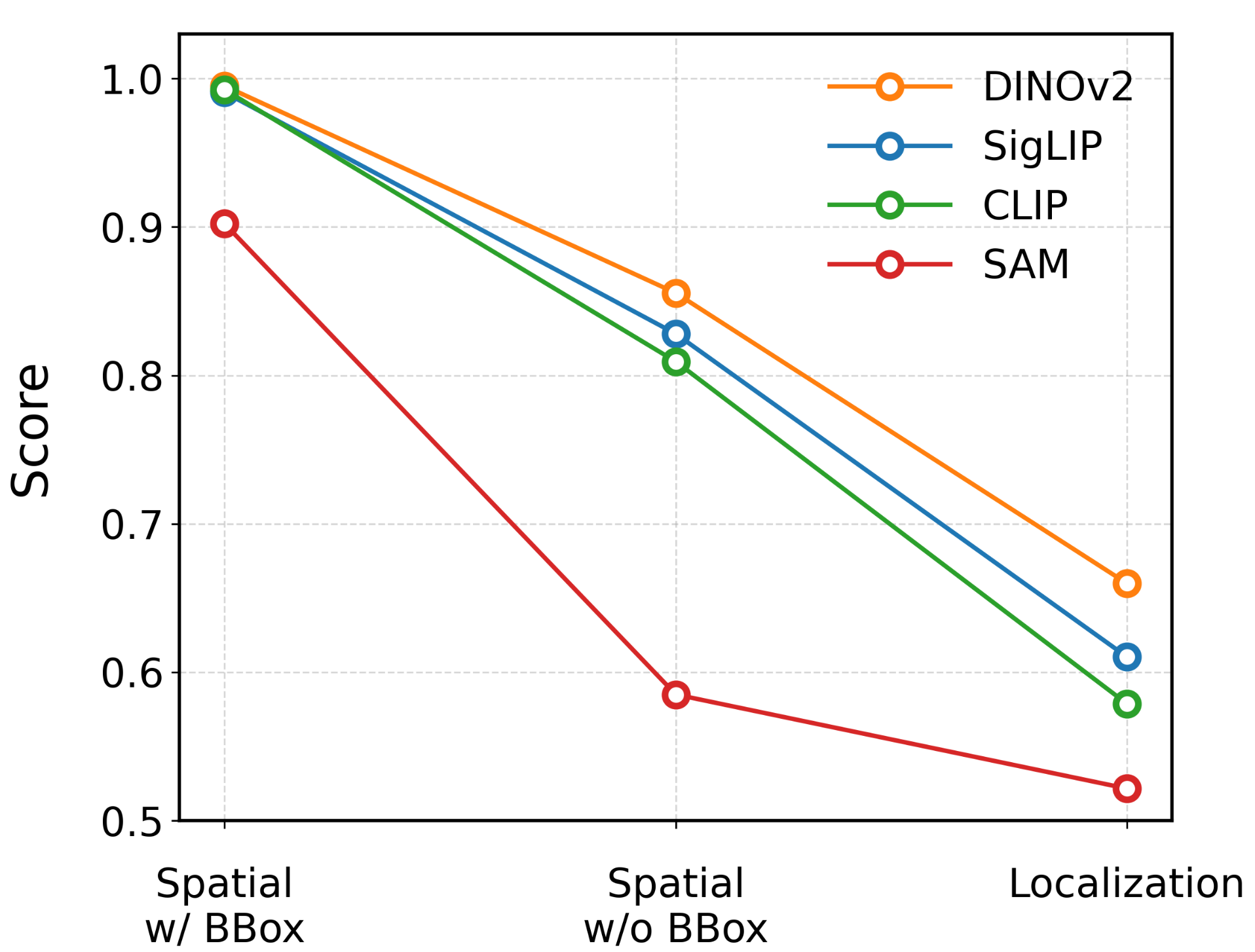
Large objects: similar performance across VFMs.
Small objects: primary performance bottleneck.
While MLLM have demonstrated remarkable versatility, they are not universally effective in all scenarios, especially in specialized domains. Thus, there is a growing necessity for developing specialized MLLMs. Currently, selecting appropriate VFMs for such customized MLLMs remains largely heuristic. Our work provides actionable insights that transform this selection process from heuristic guesswork into principled engineering. By clearly identifying AVA-specific strengths and weaknesses, practitioners can now systematically choose VFMs to precisely address the particular visual demands of targeted downstream tasks. Moreover, AVA-BENCH represents a critical step towards developing next-generation VFMs by providing a systematic, diagnostic, and comprehensive evaluation framework. This benchmark enables VFM developers to accurately pin-point specific deficiencies and implement targeted improvements, fostering the creation of more robust, versatile, and well-rounded VFMs in the future.
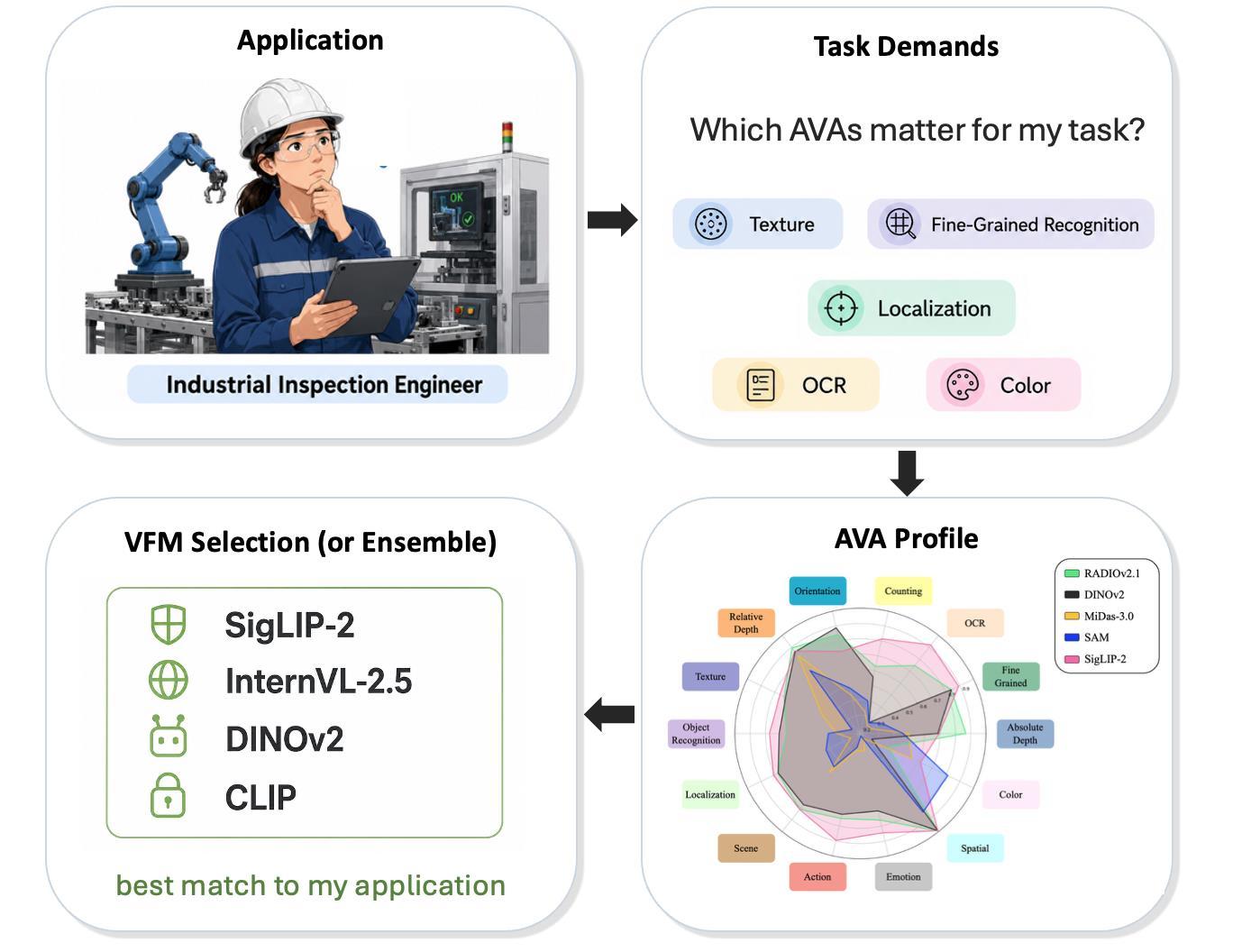
AVA-Bench makes VFM choice diagnosable, actionable, and efficient by isolating what each model can truly do.


